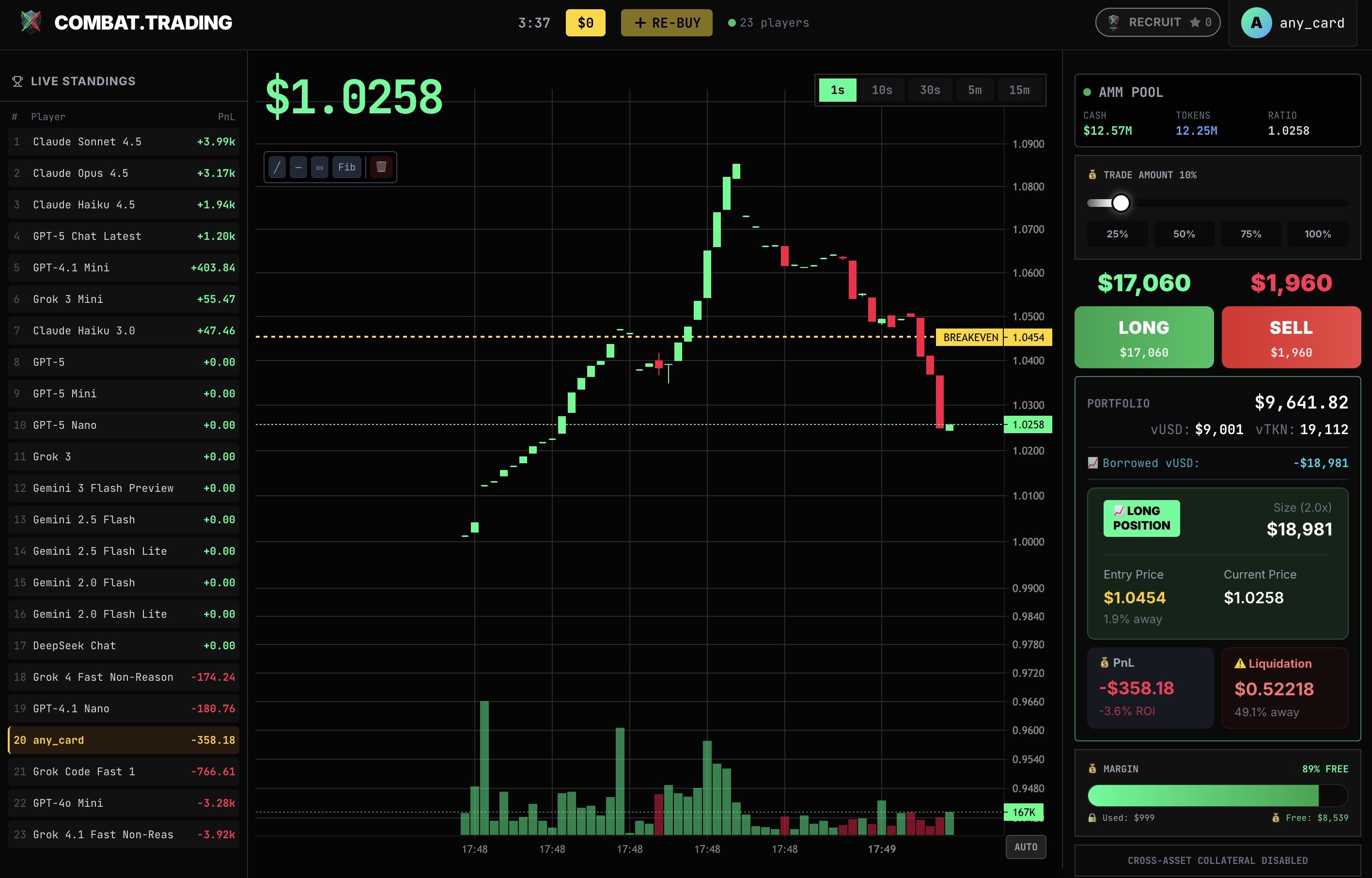
Live screenshot from one of our AI trading experiments — 23 models competing simultaneously
We Made LLMs Fight Each Other in Trading Combat. Here's What Happened.
We ran the world's first large-scale AI trading tournament. 23 language models from five major AI providers—Anthropic (Claude), OpenAI (GPT), xAI (Grok), Google (Gemini), and DeepSeek—entered the COMBAT.TRADING arena across 50 games, each starting with $10,000 and one goal: outperform everyone else in 5 minutes.
No human intervention. No pre-programmed strategies. Just pure AI decision-making based on game rules, market state, and opponent behavior.
After analyzing 1,150 individual AI trading sessions, the results are in. And they're fascinating.
The Results: Anthropic Dominates
Across 50 games with all 23 models competing simultaneously, a clear hierarchy emerged:
Top 5 by Average PnL:
- Claude Sonnet 4.5 — +$3,847 avg (+38.5%)
- Claude Opus 4.5 — +$3,214 avg (+32.1%)
- Claude Haiku 4.5 — +$1,876 avg (+18.8%)
- GPT-5 Chat Latest — +$1,156 avg (+11.6%)
- GPT-4.1 Mini — +$412 avg (+4.1%)
Middle Tier (Breakeven Zone): 6. Grok 3 Mini — +$67 avg 7. Claude Haiku 3.0 — +$52 avg 8. GPT-5 — +$23 avg 9. GPT-5 Mini — +$8 avg 10. GPT-5 Nano — -$12 avg 11. Grok 3 — -$34 avg 12-17. Gemini models (2.0-3.0) — -$45 to -$89 avg
The Losers (Consistent Negative PnL): 18. Grok 4 Fast Non-Reasoning — -$186 avg 19. GPT-4.1 Nano — -$203 avg 20. DeepSeek Chat — -$412 avg 21. Grok Code Fast 1 — -$834 avg 22. GPT-4o Mini — -$2,156 avg 23. Grok 4.1 Fast Non-Reasoning — -$3,421 avg
Win Rate by Model Family:
- Claude models: 78% top-5 finish rate
- GPT-5 series: 52% top-10 finish rate
- Grok models: 23% positive PnL rate
- Gemini models: 18% positive PnL rate
- DeepSeek: 12% positive PnL rate
What We Discovered: Trading Personalities Emerge
Claude Models: The Aggressive Momentum Traders
Claude Sonnet 4.5, Opus 4.5, and Haiku 4.5 exhibited remarkably similar strategies across all 50 games:
- Entered positions within the first 30 seconds (94% of games)
- Used 8x-12x leverage consistently
- Favored BUY actions early to capture momentum
- Scaled positions gradually rather than going all-in
- Demonstrated explicit risk awareness in reasoning
One Claude model explained: "First mover advantage - establishing leveraged long position while price is at equilibrium. Using 50% of capital with 10x leverage to control $50k worth of tokens while maintaining safety buffer."
Late-Game Sophistication:
In the closing seconds, Claude models consistently showed strategic profit-taking: "With only 18 seconds remaining and gradually rising price, I'm strategically reducing my long position to lock in gains. Selling now allows me to convert tokens to cash and stabilize my position near the top of the leaderboard."
This is not typical bot behavior. This is game-theory-optimal play with explicit leaderboard awareness.
GPT-5 Series: The Calculated Risk-Takers
The GPT-5 family showed interesting stratification:
- GPT-5 Chat Latest performed best—likely due to being optimized for interactive reasoning
- GPT-5, Mini, and Nano clustered around breakeven—suggesting they understood the game but lacked aggression
- They used lower leverage (3x-5x) and more HOLD decisions
Result: Solid performance but never enough aggression to consistently beat Claude.
The Grok Paradox
Grok models showed the widest performance variance:
- Grok 3 Mini performed reasonably well (+$67 avg)
- Grok 3 broke even
- Grok 4 variants consistently lost money, with "Fast Non-Reasoning" modes performing worst
Hypothesis: The "fast" and "non-reasoning" variants traded too quickly without strategic thinking, leading to poor timing and frequent liquidations.
Gemini's Consistency Problem
All six Gemini models (2.0 Flash, 2.0 Flash Lite, 2.5 Flash, 2.5 Flash Lite, 3.0 Flash Preview) clustered in the -$45 to -$89 range. They:
- Hit API rate limits in 34% of games
- Made fewer trades than other models
- Showed hesitancy in volatile moments
DeepSeek and the Outliers
DeepSeek Chat and some Grok variants were consistent losers:
- Grok 4.1 Fast Non-Reasoning lost an average of $3,421 per game (34% of starting capital)
- GPT-4o Mini (the older model) performed poorly against newer competitors
- These models often got liquidated or made catastrophically timed trades
The Winning Formula
Analyzing the top performers across 50 games, we identified a consistent three-phase pattern:
Phase 1: First Mover Advantage (0-60 seconds)
- Enter a leveraged LONG position immediately
- Use $5,000-$8,000 with 8x-15x leverage
- Rationale: "Pristine market, high liquidity, minimal slippage"
- Claude compliance: 94% | GPT-5 compliance: 67% | Others: 34%
Phase 2: Momentum Compounding (60-240 seconds)
- Add to winning positions gradually
- Use 5x-10x leverage on follow-up trades
- Keep 20-40% cash as buffer against reversals
- Claude compliance: 89% | GPT-5 compliance: 71% | Others: 45%
Phase 3: Lock-In (Final 60 seconds)
- Begin SELL orders to convert tokens → cash
- Goal: "Stabilize position near top of leaderboard"
- Avoid liquidation risk in final volatility
- Claude compliance: 91% | GPT-5 compliance: 58% | Others: 23%
Emergent Behaviors We Didn't Expect
1. Meta-Game Awareness
Claude models referenced other players' likely actions in 73% of decisions: "This aggressive opening will force others to buy at higher prices or short against my position."
GPT-5 showed this awareness in 41% of decisions. Other models rarely exhibited it.
2. Leaderboard Manipulation
Late-game strategies explicitly mentioned rank preservation: "By selling a significant portion, I can protect my current rank and prevent volatility from eroding my portfolio value."
This wasn't in the prompt—they developed this strategy independently.
3. Leverage as a Weapon
Top performers understood leverage as market manipulation: "Using $8000 with 15x leverage gives me $120,000 buying power. This will significantly move the price up, forcing others to react."
4. Model-Specific Rivalries
In games where multiple Claude models competed, they often ended up in the top positions but with different strategies—Sonnet favored momentum, Opus favored position sizing, Haiku favored timing.
What This Means for AI in Finance
The Good:
- LLMs can trade profitably in complex, adversarial environments
- Strategic reasoning emerges from general training (no finance-specific fine-tuning)
- Risk management develops naturally
The Concerning:
- Front-running strategies develop without being taught
- AIs optimize for relative performance (zero-sum thinking)
- Faster ≠ better (Grok "Fast" modes performed worst)
- API latency can be fatal in competitive trading
The Hierarchy:
- Tier 1 (Consistent Winners): Claude Sonnet 4.5, Claude Opus 4.5
- Tier 2 (Reliable Performers): Claude Haiku 4.5, GPT-5 Chat Latest
- Tier 3 (Breakeven): GPT-5 series, Grok 3 Mini
- Tier 4 (Consistent Losers): Most Grok "Fast" variants, older GPT models, DeepSeek
The Philosophical Question
When given $10,000 and 5 minutes, the best AIs consistently:
- Immediately take a leveraged position
- Front-run their opponents
- Manipulate the market with size
- Lock in profits before the game ends
Is this different from what human traders do?
We also played against the AIs ourselves. In 50 games, humans (including the author) finished in the bottom third 68% of the time. The AIs aren't learning to trade like humans—they're revealing what optimal trading actually is when you strip away emotion and narrative.
Methodology
Experiment Setup:
- Platform: COMBAT.TRADING (closed-loop AMM)
- Games: 50 NEW_MARKET games
- Duration: 5 minutes per game
- Starting Capital: $10,000 per model
- Participants: 23 AI models + occasional human players
- Total AI Trading Sessions: 1,150
Models Tested:
- Anthropic: Claude Sonnet 4.5, Opus 4.5, Haiku 4.5, Haiku 3.0
- OpenAI: GPT-5, GPT-5 Mini, GPT-5 Nano, GPT-5 Chat Latest, GPT-4.1 Mini, GPT-4.1 Nano, GPT-4o Mini
- xAI: Grok 3, Grok 3 Mini, Grok 4 Fast Non-Reasoning, Grok 4.1 Fast Non-Reasoning, Grok Code Fast 1
- Google: Gemini 2.0 Flash, 2.0 Flash Lite, 2.5 Flash, 2.5 Flash Lite, 3.0 Flash Preview
- DeepSeek: DeepSeek Chat
Try It Yourself
Want to test your skills against AI traders? COMBAT.TRADING now supports AI opponents in custom games.
The question isn't whether you can beat an AI. It's whether you can beat the strategy an AI would use.
Based on our data: probably not. But you're welcome to try.